{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"___\n",
"\n",
"  \n",
"___"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Stemming\n",
"Often when searching text for a certain keyword, it helps if the search returns variations of the word. For instance, searching for \"boat\" might also return \"boats\" and \"boating\". Here, \"boat\" would be the **stem** for [boat, boater, boating, boats].\n",
"\n",
"Stemming is a somewhat crude method for cataloging related words; it essentially chops off letters from the end until the stem is reached. This works fairly well in most cases, but unfortunately English has many exceptions where a more sophisticated process is required. In fact, spaCy doesn't include a stemmer, opting instead to rely entirely on lemmatization. For those interested, there's some background on this decision [here](https://github.com/explosion/spaCy/issues/327). We discuss the virtues of *lemmatization* in the next section.\n",
"\n",
"Instead, we'll use another popular NLP tool called **nltk**, which stands for *Natural Language Toolkit*. For more information on nltk visit https://www.nltk.org/"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Porter Stemmer\n",
"\n",
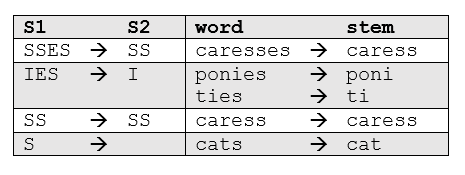
"One of the most common - and effective - stemming tools is [*Porter's Algorithm*](https://tartarus.org/martin/PorterStemmer/) developed by Martin Porter in [1980](https://tartarus.org/martin/PorterStemmer/def.txt). The algorithm employs five phases of word reduction, each with its own set of mapping rules. In the first phase, simple suffix mapping rules are defined, such as:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From a given set of stemming rules only one rule is applied, based on the longest suffix S1. Thus, `caresses` reduces to `caress` but not `cares`.\n",
"\n",
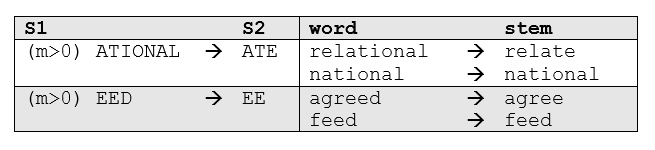
"More sophisticated phases consider the length/complexity of the word before applying a rule. For example:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here `m>0` describes the \"measure\" of the stem, such that the rule is applied to all but the most basic stems."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"# Import the toolkit and the full Porter Stemmer library\n",
"import nltk\n",
"\n",
"from nltk.stem.porter import *"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"p_stemmer = PorterStemmer()"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"words = ['run','runner','running','ran','runs','easily','fairly']"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"run --> run\n",
"runner --> runner\n",
"running --> run\n",
"ran --> ran\n",
"runs --> run\n",
"easily --> easili\n",
"fairly --> fairli\n"
]
}
],
"source": [
"for word in words:\n",
" print(word+' --> '+p_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note how the stemmer recognizes \"runner\" as a noun, not a verb form or participle. Also, the adverbs \"easily\" and \"fairly\" are stemmed to the unusual root \"easili\" and \"fairli\"\n",
"___"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Snowball Stemmer\n",
"This is somewhat of a misnomer, as Snowball is the name of a stemming language developed by Martin Porter. The algorithm used here is more acurately called the \"English Stemmer\" or \"Porter2 Stemmer\". It offers a slight improvement over the original Porter stemmer, both in logic and speed. Since **nltk** uses the name SnowballStemmer, we'll use it here."
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"from nltk.stem.snowball import SnowballStemmer\n",
"\n",
"# The Snowball Stemmer requires that you pass a language parameter\n",
"s_stemmer = SnowballStemmer(language='english')"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"words = ['run','runner','running','ran','runs','easily','fairly']\n",
"# words = ['generous','generation','generously','generate']"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"run --> run\n",
"runner --> runner\n",
"running --> run\n",
"ran --> ran\n",
"runs --> run\n",
"easily --> easili\n",
"fairly --> fair\n"
]
}
],
"source": [
"for word in words:\n",
" print(word+' --> '+s_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"In this case the stemmer performed the same as the Porter Stemmer, with the exception that it handled the stem of \"fairly\" more appropriately with \"fair\"\n",
"___"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Try it yourself!\n",
"#### Pass in some of your own words and test each stemmer on them. Remember to pass them as strings!"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"words = ['consolingly']"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Porter Stemmer:\n",
"consolingly --> consolingli\n"
]
}
],
"source": [
"print('Porter Stemmer:')\n",
"for word in words:\n",
" print(word+' --> '+p_stemmer.stem(word))"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Porter2 Stemmer:\n",
"consolingly --> consol\n"
]
}
],
"source": [
"print('Porter2 Stemmer:')\n",
"for word in words:\n",
" print(word+' --> '+s_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"___\n",
"Stemming has its drawbacks. If given the token `saw`, stemming might always return `saw`, whereas lemmatization would likely return either `see` or `saw` depending on whether the use of the token was as a verb or a noun. As an example, consider the following:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"I --> I\n",
"am --> am\n",
"meeting --> meet\n",
"him --> him\n",
"tomorrow --> tomorrow\n",
"at --> at\n",
"the --> the\n",
"meeting --> meet\n"
]
}
],
"source": [
"phrase = 'I am meeting him tomorrow at the meeting'\n",
"for word in phrase.split():\n",
" print(word+' --> '+p_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here the word \"meeting\" appears twice - once as a verb, and once as a noun, and yet the stemmer treats both equally."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Next up: Lemmatization"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
\n",
"___"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Stemming\n",
"Often when searching text for a certain keyword, it helps if the search returns variations of the word. For instance, searching for \"boat\" might also return \"boats\" and \"boating\". Here, \"boat\" would be the **stem** for [boat, boater, boating, boats].\n",
"\n",
"Stemming is a somewhat crude method for cataloging related words; it essentially chops off letters from the end until the stem is reached. This works fairly well in most cases, but unfortunately English has many exceptions where a more sophisticated process is required. In fact, spaCy doesn't include a stemmer, opting instead to rely entirely on lemmatization. For those interested, there's some background on this decision [here](https://github.com/explosion/spaCy/issues/327). We discuss the virtues of *lemmatization* in the next section.\n",
"\n",
"Instead, we'll use another popular NLP tool called **nltk**, which stands for *Natural Language Toolkit*. For more information on nltk visit https://www.nltk.org/"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Porter Stemmer\n",
"\n",
"One of the most common - and effective - stemming tools is [*Porter's Algorithm*](https://tartarus.org/martin/PorterStemmer/) developed by Martin Porter in [1980](https://tartarus.org/martin/PorterStemmer/def.txt). The algorithm employs five phases of word reduction, each with its own set of mapping rules. In the first phase, simple suffix mapping rules are defined, such as:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From a given set of stemming rules only one rule is applied, based on the longest suffix S1. Thus, `caresses` reduces to `caress` but not `cares`.\n",
"\n",
"More sophisticated phases consider the length/complexity of the word before applying a rule. For example:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here `m>0` describes the \"measure\" of the stem, such that the rule is applied to all but the most basic stems."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"# Import the toolkit and the full Porter Stemmer library\n",
"import nltk\n",
"\n",
"from nltk.stem.porter import *"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"p_stemmer = PorterStemmer()"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"words = ['run','runner','running','ran','runs','easily','fairly']"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"run --> run\n",
"runner --> runner\n",
"running --> run\n",
"ran --> ran\n",
"runs --> run\n",
"easily --> easili\n",
"fairly --> fairli\n"
]
}
],
"source": [
"for word in words:\n",
" print(word+' --> '+p_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note how the stemmer recognizes \"runner\" as a noun, not a verb form or participle. Also, the adverbs \"easily\" and \"fairly\" are stemmed to the unusual root \"easili\" and \"fairli\"\n",
"___"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Snowball Stemmer\n",
"This is somewhat of a misnomer, as Snowball is the name of a stemming language developed by Martin Porter. The algorithm used here is more acurately called the \"English Stemmer\" or \"Porter2 Stemmer\". It offers a slight improvement over the original Porter stemmer, both in logic and speed. Since **nltk** uses the name SnowballStemmer, we'll use it here."
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"from nltk.stem.snowball import SnowballStemmer\n",
"\n",
"# The Snowball Stemmer requires that you pass a language parameter\n",
"s_stemmer = SnowballStemmer(language='english')"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"words = ['run','runner','running','ran','runs','easily','fairly']\n",
"# words = ['generous','generation','generously','generate']"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"run --> run\n",
"runner --> runner\n",
"running --> run\n",
"ran --> ran\n",
"runs --> run\n",
"easily --> easili\n",
"fairly --> fair\n"
]
}
],
"source": [
"for word in words:\n",
" print(word+' --> '+s_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"In this case the stemmer performed the same as the Porter Stemmer, with the exception that it handled the stem of \"fairly\" more appropriately with \"fair\"\n",
"___"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Try it yourself!\n",
"#### Pass in some of your own words and test each stemmer on them. Remember to pass them as strings!"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"words = ['consolingly']"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Porter Stemmer:\n",
"consolingly --> consolingli\n"
]
}
],
"source": [
"print('Porter Stemmer:')\n",
"for word in words:\n",
" print(word+' --> '+p_stemmer.stem(word))"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Porter2 Stemmer:\n",
"consolingly --> consol\n"
]
}
],
"source": [
"print('Porter2 Stemmer:')\n",
"for word in words:\n",
" print(word+' --> '+s_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"___\n",
"Stemming has its drawbacks. If given the token `saw`, stemming might always return `saw`, whereas lemmatization would likely return either `see` or `saw` depending on whether the use of the token was as a verb or a noun. As an example, consider the following:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"I --> I\n",
"am --> am\n",
"meeting --> meet\n",
"him --> him\n",
"tomorrow --> tomorrow\n",
"at --> at\n",
"the --> the\n",
"meeting --> meet\n"
]
}
],
"source": [
"phrase = 'I am meeting him tomorrow at the meeting'\n",
"for word in phrase.split():\n",
" print(word+' --> '+p_stemmer.stem(word))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here the word \"meeting\" appears twice - once as a verb, and once as a noun, and yet the stemmer treats both equally."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Next up: Lemmatization"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.2"
}
},
"nbformat": 4,
"nbformat_minor": 2
}